
泛型程序设计与C++标准模版库(STL)
泛型程序设计及STL结构
泛性程序设计的基本概念
即指编写不依赖具体数据类型的程序,模板是泛性程序设计的主要工具。
术语:概念
用来界定具备一定功能的数据类型。例如:
- 将“可以比大小的所有数据类型(有比较运算符)”这一概念记为Comparable
- 将“具有公有的复制构造函数并可以用‘=’赋值的数据类型”这一概念 记为Assignable
- 将“可以比大小、具有公有的复制构造函数并可以用‘=’赋值的所有数 据类型”这个概念记作Sortable。
对于两个不同的概念A和B,如果概念A所需求的所有功能也是概念B所需求的功能,那么就说概念B是概念A的子概念。例如:
- Sortable既是Comparable的子概念,也是Assignable的子概念
其实这个子概念和基类派生的子类意思差不多。
术语:模型
模型(model):符合一个概念的数据类型称为该概念的模型
- int型是Comparable概念的模型;
- 静态数组类型不是Assignable概念的类型(静态数组不可赋值)。
用概念做模板参数名
- 很多STL的实现代码就是使用概念来命名模板参数的。
- 为概念赋予一个名称,并使用该名称作为模板参数名。
例如:
表示insertionSort这样一个函数模板的原型:
1 | template <class Sortable> |
STL简介
标准模版库提供了一些非常常用的数据结构和算法。
STL的基本组件:
- 容器(container)
- 迭代器(iterator)
- 函数对象(function object)
- 算法(algorithms)
基本的关系:
- Iterator(迭代器)是算法和容器的桥梁。将迭代器作为算法的参数、通过迭代器来访问容器而不是把容器直接作为算法的参数;
- 将函数对象作为算法的参数而不是将函数所执行的运算作为算法的一部分。
关系图:
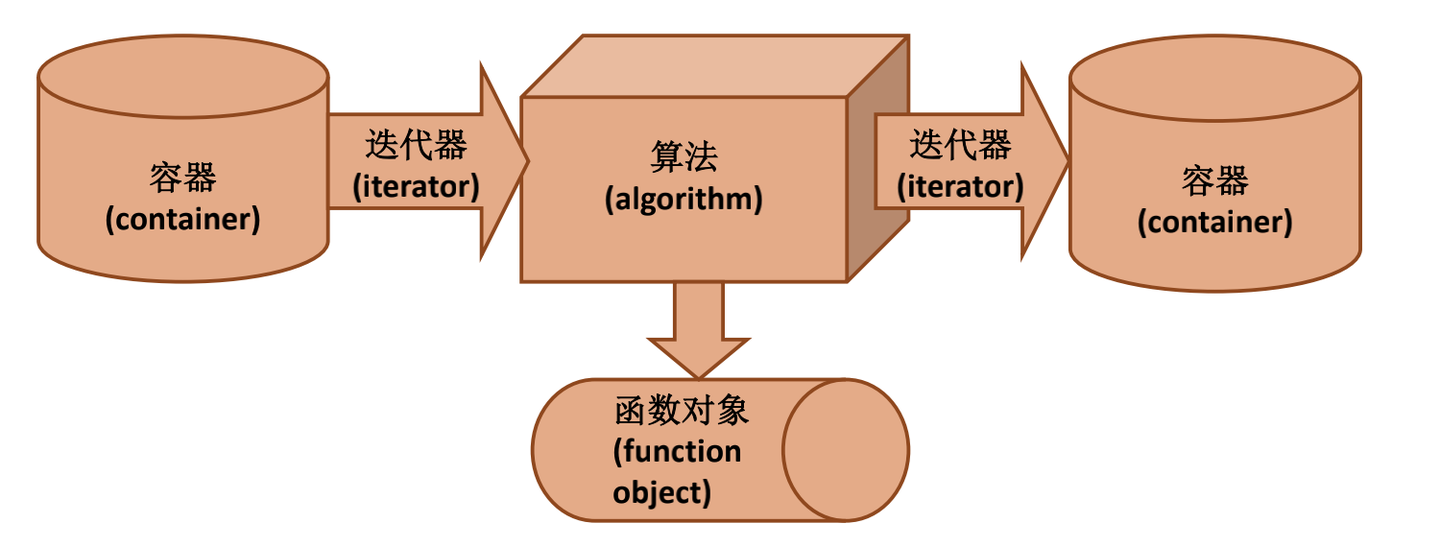
STL的基本组件—容器(container)
容器是容纳一组元素的对象,容器类库包含七种基本容器:向量(vector)、双端队列(deque)、列表(list)、集合(set)、多重集合(multiset)、map(映射)和多重映射(multimap)。
- 顺序容器:array,vector,deque,forward_list(单链表)、list(列表,底层是双向链表) ;
- 有序关联容器:set、multiset、map、multimap;
- 无序关联容器:unordered_set、unordered_multiset、unordered_map、unordered_mutimap。
容器适配器:stack、queue、priority_queue(优先队列,底层是最大或最小二叉堆)
使用容器,需要包含对应的头文件。
STL的基本组件—迭代器(iterator)
- 迭代器是泛化的指针,提供了顺序访问容器中每个元素的方法;
- 提供了顺序访问容器中每个元素的方法;
- 可以使用“++”运算符来获得指向下一个元素的迭代器;
- 可以使用“*”运算符访问一个迭代器所指向的元素,如果元素类型是类或结构体,还可以使用“->”运算符直接访问该元素的一个成员;
- 有些迭代器还支持通过“–”运算符获得指向上一个元素的迭代器;
- 迭代器是泛化的指针:指针也具有同样的特性,因此指针本身就是一种迭代器;
- 使用独立于STL容器的迭代器,需要包含头文件
<iterator>。
STL的基本组件—函数对象(function object)
- 一个行为类似函数的对象,对它可以像调用函数一样调用。
- 函数对象是泛化的函数:任何普通的函数和任何重载了“()” 运算符的类的对象都可以作为函数对象使用。
- 使用STL的函数对象,需要包含头文件
<functional>。
STL的基本组件—算法(algorithms)
- STL包括70多个算法,例如:排序算法,消除算法,计数算法,比较算法,变换算法,置换算法和容器管理等;
- 可以广泛用于不同的对象和内置的数据类型;
- 使用STL的算法,需要包含头文件
<algorithm>。
算法举例—transform算法
transform算法顺序遍历first和last两个迭代器所指向的元素;
- 将每个元素的值作为函数对象op的参数;
- 将op的返回值通过迭代器result顺序输出;
- 遍历完成后result迭代器指向的是输出的最后一个元素的下一个位置,transform会将该迭代器返回。
例如,以下可以是transform算法的一种实现:
1 | template <class InputIterator, class OutputIterator, class UnaryFunction> |
实例:
1 | //从标准输入读入几个整数,存入向量容器,输出相反数 |
迭代器
迭代器是算法和容器的桥梁:
- 迭代器用作访问容器中的元素
- 算法不直接操作容器中的数据,而是通过迭代器间接操作
算法和容器独立:
- 增加新的算法,无需影响容器的实现
- 增加新的容器,原有的算法也能适用
输入流迭代器和输出流迭代器
输入流迭代器
stream_iterator<T>- 以输入流(如cin)为参数构造
- 可用*(p++)获得下一个输入的元素
输出流迭代器 ostream_iterator<T>- 构造时需要提供输出流(如cout)
- 可用(*p++) = x将x输出到输出流
二者都属于适配器
- 适配器是用来为已有对象提供新的接口的对象
- 输入流适配器和输出流适配器为流对象提供了迭代器的接口
程序实例:
1 | //从标准输入读入几个实数,分别输出他们的平方 |
迭代器的分类
根据访问的方式分类:
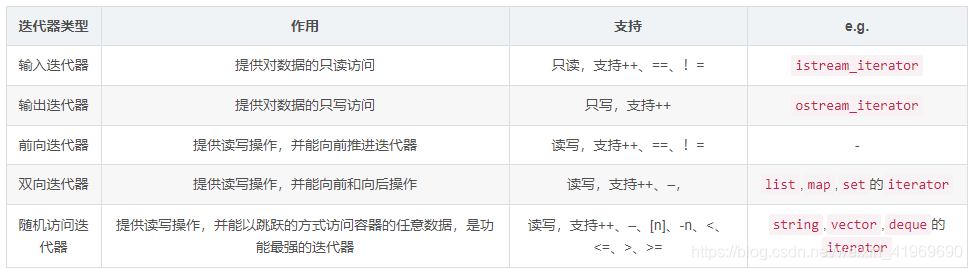
关系图:
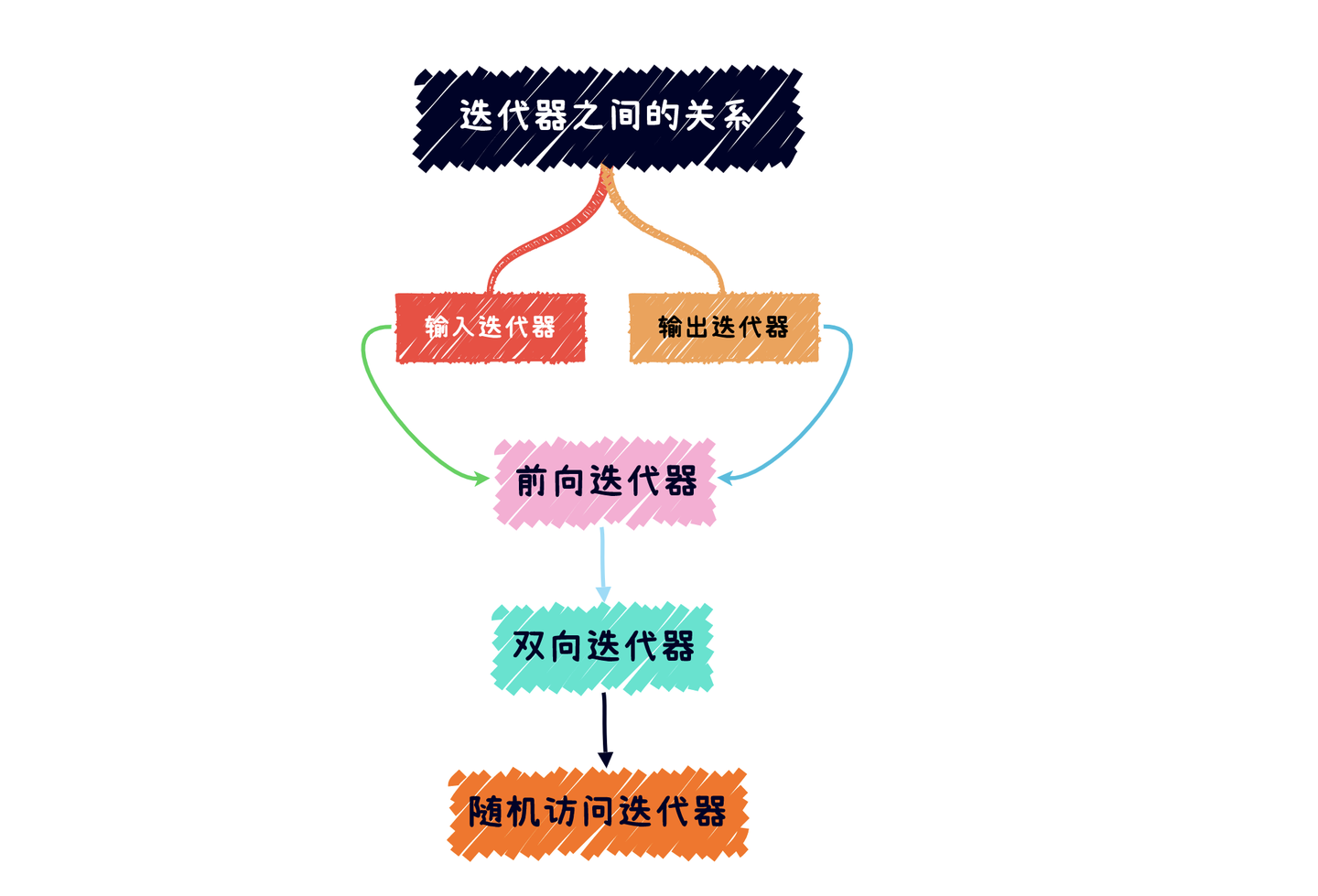
根据操作类型分类:

迭代器的区间
- 两个迭代器表示一个区间:[p1, p2),区间包含p1,但不包含p2;
- STL算法常以迭代器的区间作为输入,传递输入数据;
- 合法的区间:p1经过n次(n > 0)自增(++)操作后满足p1 == p2。
程序实例:
1 | //综合运用集中迭代器的实例 |
迭代器的辅助函数
- advance(p,n):对p执行n次自增操作
- distance(first,last):计算两个迭代器first和last的距离
容器
容器的基本功能与分类
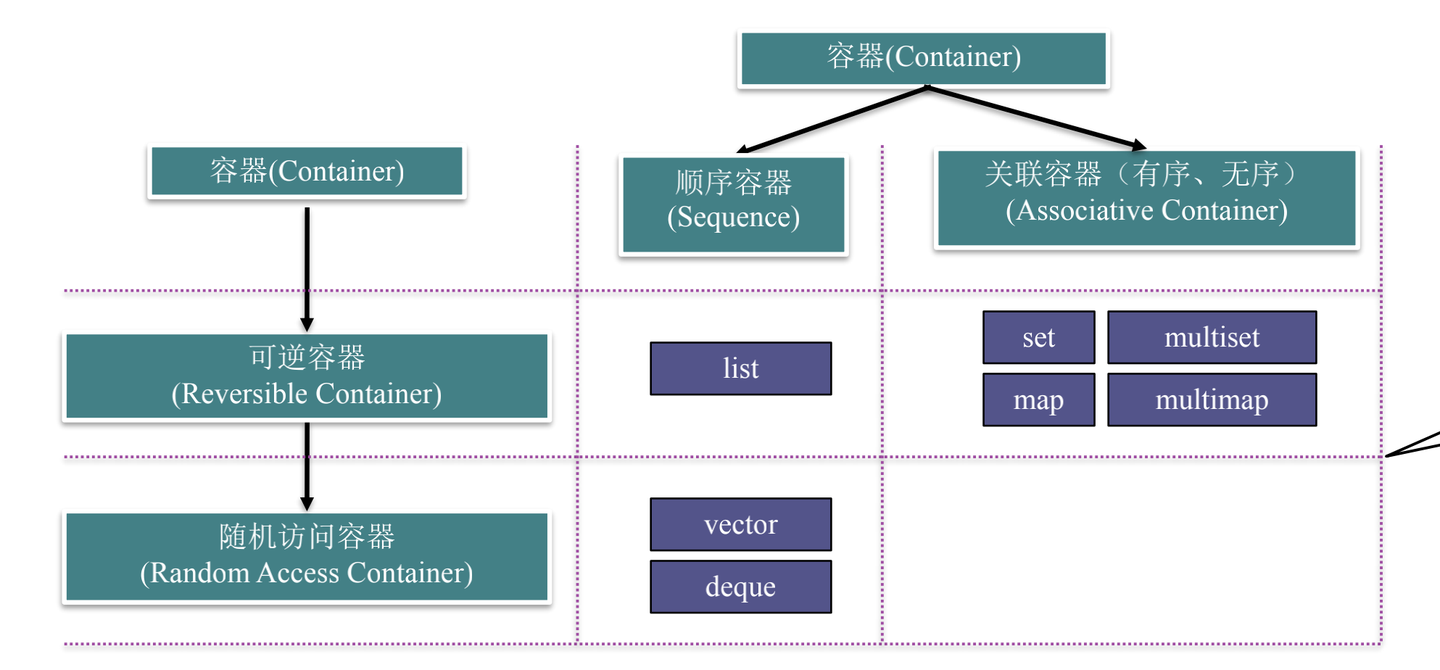
容器的通用功能
- 用默认构造函数构造空容器
- 支持关系运算符:==、!=、<、<=、>、>=
- begin()、end():获得容器首、尾迭代器(其实指向的是容器尾元素的下一个元素)
- cbegin() 、cend():获取容器首、尾常迭代器,不需要改变容器时更加安全
- clear():将容器清空
- empty():判断容器是否为空
- size():得到容器元素个数
- s1.swap(s2):将s1和s2两容器内容交换
相关数据类型(S表示容器类型)
- S::iterator:指向容器元素的迭代器类型
- S::const_iterator:常迭代器类型
使用一般容器的begin()/end(),得到的迭代器都是前向迭代器,而可逆容器所提供的迭代器都是双向迭代器。
事实上,STL模版提供的标准容器至少都是可逆容器,但有些非标准的模版库,提供像slist(单向链表)这样仅提供前向迭代器的容器。
对可逆容器的访问
STL为每个可逆容器都提供了逆向迭代器,逆向迭代器可以通过下面的成员函数得到:
- rbegin() :指向容器尾的逆向迭代器
- rend():指向容器首的逆向迭代器
逆向迭代器的类型名的表示方式如下(S表示容器类型):
- S::reverse_iterator:逆向迭代器类型
- S::const_reverse_iterator:逆向常迭代器类型
逆向迭代器是普通迭代器的适配器,逆向迭代器的++被映射成了前向迭代器的–。
细节:
一个迭代器和它的逆向迭代器之间可以相互转换。例如:若p1是S::iterator类型的迭代器,则使用表达式S::reverse_iterator(p1)可以得到与p1对应的逆向迭代器;也可以使用base函数得到逆向迭代器对应的那个普通迭代器,如:r1是一个通过S::reverse_iterator(p1)构造的逆向迭代器,那么就有r1.base() == p1。但是r1和p1并不是指向同一个元素的,r1指向的元素总是与p1-1所指向的元素相同。
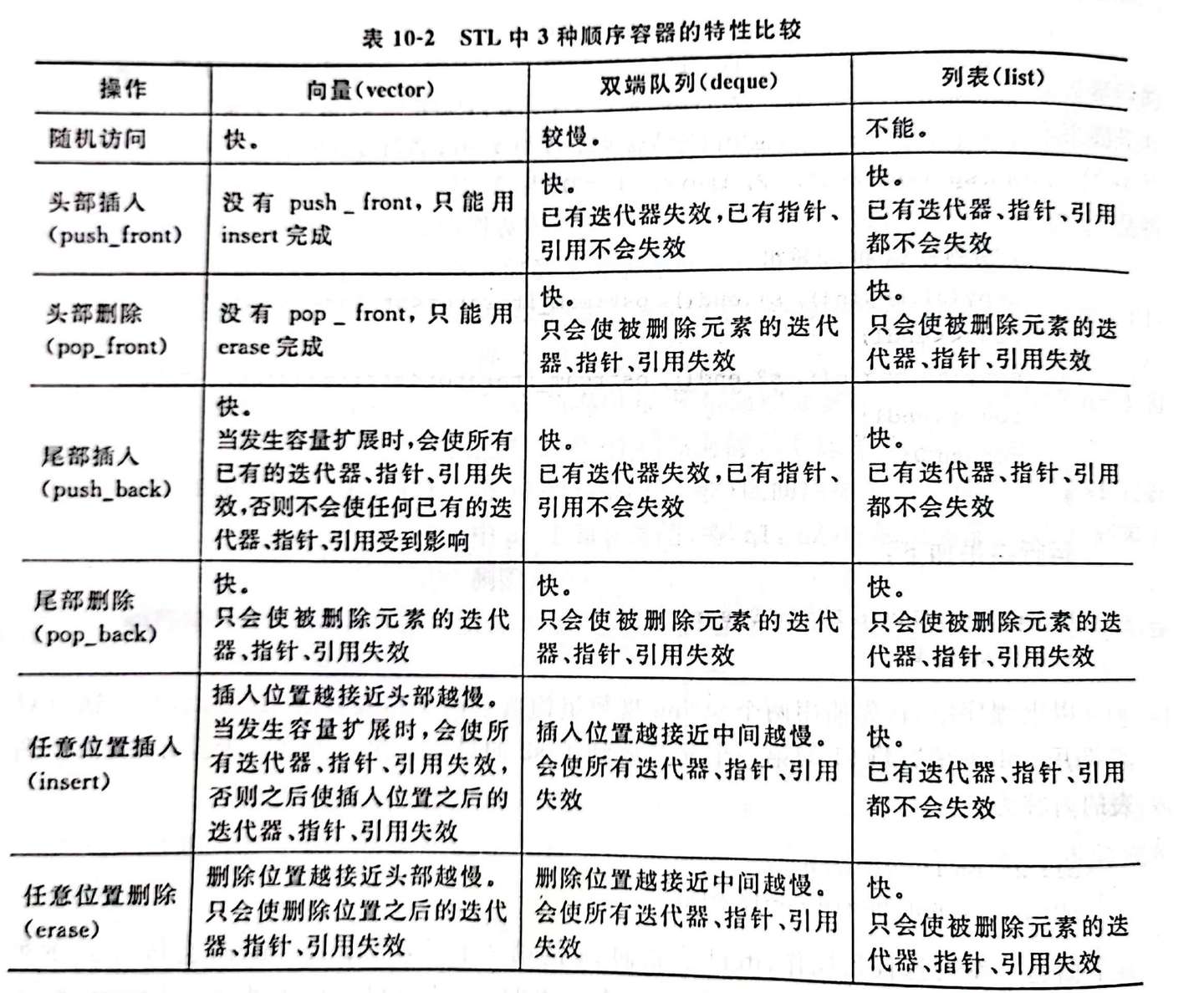
顺序容器
STL中的顺序容器
-
向量(vector)
-
双端队列(deque)
-
列表(list)
-
单向链表(forward_list)
-
数组(array)
-
元素线性排列,可以随时在指定位置插入元素和删除元素。
-
必须符合Assignable这一概念(即具有公有的复制构造函数并可以
用“=”赋值)。 -
array对象的大小固定,forward_list有特殊的添加和删除操作。
顺序容器的接口
不包含单向链表(forward_list)和数组(array)
- 构造函数
- 列表初始化,如
vector<int> arr = {1,4,5,7};
- 列表初始化,如
- 赋值函数
- assign
- 插入函数
insert(iterator pos, const T& v), 在pos位置插入后,返回新插入元素的迭代器;- push_front(只对list和deque), push_back;
- emplace_front、emplace 和 emplace_back,这些操作构造而不是拷贝元素到容器中,这些操作分别对应push_front、insert 和push_back,允许我们将元素放在容器头部、一个指定的位置和容器尾部。
- 删除函数
- erase,clear,pop_front(只对list和deque),pop_back
- 首尾元素的直接访问
- front,back
- 改变大小
- resize
记住对于头部的操作不适合物理地址连续的数据结构。
向量(vector)
特点:
- 一个可以扩展的动态数组
- 随机访问、在尾部插入或删除元素快
- 在中间或头部插入或删除元素慢
向量的容量(capacity):实际分配空间的大小
- s.capacity() :返回当前容量
- s.reserve(n):若容量小于n,则对s进行扩展,使其容量至少为n
- s.shrink_to_fit(): 回收未使用的元素空间,即size和capacity函数返回值相等
失效:
如果加入元素使得vector有扩展的话,那么所有的迭代器,指针和引用都会失效,因为内存空间被重新分配了;如果没有扩展,那么只是插入(或删除)的元素之后的迭代器等等会失效(因为元素被移动了)。
双端队列(deque)
特点
- 在两端插入或删除元素快
- 在中间插入或删除元素慢
- 随机访问较快,但比向量容器慢
双端队列在很多STL的实现中是一个分段数组,容器中的元素分段的存放在一个个大小固定的数组中,此外容器还需要维护一个存这些分段数组首地址的索引数组,所以双端队列连续是一个假象。

1 | //先按照从大到小顺序输出奇数,再按照从小到大顺序输出偶数。 |
列表(list)
底层逻辑是双向链表。
特点
- 在任意位置插入和删除元素都很快
- 不支持随机访问
接合(splice)操作s1.splice(p, s2, q1, q2)表示将s2中[q1, q2)移动到s1中p所指向元素之前
单向链表(forward_list)
特点:
- 单向链表每个结点只有指向下个结点的指针,没有简单的方法来获取一个结点的前驱;
- 未定义insert、emplace和erase操作,而定义了insert_after、emplace_after和erase_after操作,其参数与list的insert、emplace和erase相同,但并不是插入或删除迭代器p1所指的元素,而是对p1所指元素之后的结点进行操作;
- 不支持size操作。
数组(array)
特点:
- array是对内置数组的封装,提供了更安全,更方便的使用数组的方式
- array的对象的大小是固定的,定义时除了需要指定元素类型,还需要指定容器大小。
- 不能动态地改变容器大小
顺序容器的插入迭代器与适配器
顺序容器的插入迭代器
概念:用于向容器头部、尾部或中间指定位置插入元素的迭代器,包括前插迭代器(front_inserter)、后插迭代器(back_insrter)和任意位置插入迭代器(inserter)。
1 | list<int> s; |
顺序容器的适配器
以顺序容器胃基础构建一些常用的数据结构,是对顺序容器的封装:
- 栈(stack):最先压入的元素最后被弹出
- 队列(queue):最先压入的元素最先被弹出
- 优先级队列(priority_queue):最“大”的元素最先被弹出
栈可以用任何一种顺序容器作为基础容器,但是队列只允许用前插顺序容器(双端队列或列表)
优先级队列的本质是最大(小)二叉堆。
栈和队列共同支持的操作
- s1 op s2 op可以是==、!=、<、<=、>、>=之一,它会对两个容器适配器之间的元素按字典序进行比较;
- s.size() 返回s的元素个数;
- s.empty() 返回s是否为空;
- s.push(t) 将元素t压入到s中;
- s.pop() 将一个元素从s中弹出,对于栈来说,每次弹出的是最后被压入的元素,而对于队列,每次被弹出的是最先被压入的元素;
- 不支持迭代器,因为它们不允许对任意元素进行访问。
栈和队列的不同操作
栈的操作:
- s.top() 返回栈顶元素的引用
队列操作:
- s.front() 获得队头元素的引用
- s.back() 获得队尾元素的引用
优先级队列
优先级队列也像栈和队列一样支持元素的压入和弹出,但元素弹出的顺序与元素的大小有关,每次弹出的总是容器中最“大”的一个元素。
1 | template <class T, class Sequence = vector<T> |
优先级队列的基础容器必须是支持随机访问的顺序容器。
- 支持栈和队列的size、empty、push、pop几个成员函数,用法与栈和队列相同。
- 优先级队列并不支持比较操作。
- 与栈类似,优先级队列提供一个top函数,可以获得下一个即将被弹出元素(即最“大”的元素)的引用。
关联容器
关联容器的分类和基本功能
对于关联容器而言,每个元素都有一个键(key),容器中元素的顺序是按照键取值的升序排列的。
与顺序容器查找元素的时间复杂度不同,关联容器会把元素根据键的大小组织成一颗平衡二叉树,时间复杂度为。
有序关联容器的分类:
- 单重关联容器(set和map)
- 键值是唯一的,一个键值只能对应一个元素
- 多重关联容器(multiset和multimap)
- 键值是不唯一的,一个键值可以对应多个元素
- 简单关联容器(set和multiset)
- 容器只有一个类型参数,如set<K>、multiset<K>,表示键类型
- 容器的元素就是键本身
- 二元关联容器(map和multimap)
- 容器有两个类型参数,如map<K,V>、multimap<K,V>,分别表示键和附加数据的类型
- 容器的元素类型是pair<K,V>,即由键类型和附加数据类型复合而成的二元组
接口
- 构造:列表初始化,如
map<string, int> id_map = {{"小明", 1}, {"李华", 2}} - 插入:insert
- 删除:erase
- 查找:find
- 定界:lower_bound、upper_bound、equal_range
- 计数:count
C++11新标准中定义了4个无序关联容器
unordered_set、unordered_map、unordered_multiset、unordered_multimap
- 不是使用比较运算符来组织元素的,而是通过一个哈希函数和键类型的==运算符。
- 提供了与有序容器相同的操作
- 可以直接定义关键字是内置类型的无序容器。
- 不能直接定义关键字类型为自定义类的无序容器,如果需要,必须提供我们自己的hash模板。
集合(set)
集合用来存储一组无重复的元素。由于集合的元素本身是有序的,可以高效地查找指定元素,也可以方便地得到指定大小范围的元素在容器中所处的区间。
1 | pair<set<double>::iterator,bool> r=s.insert(v); |
映射(map)
映射与集合同属于单重关联容器,它们的主要区别在于,集合的元素类型是键本身,而映射的元素类型是由键和附加数据所构成的二元组。
在集合中按照键查找一个元素时,一般只是用来确定这个元素是否存在,而在映射中按照键查找一个元素时,除了能确定它的存在性外,还可以得到相应的附加数据。
1 | courses.insert(make_pair("CSAPP", 3)); |
多重集合(multiset)与多重映射(multimap)
多重集合是允许有重复元素的集合,多重映射是允许一个键对应多个附加数据的映射。
多重集合与集合、多重映射与映射的用法差不多,只在几个成员函数上有细微差异,其差异主要表现在去除了键必须唯一的限制。
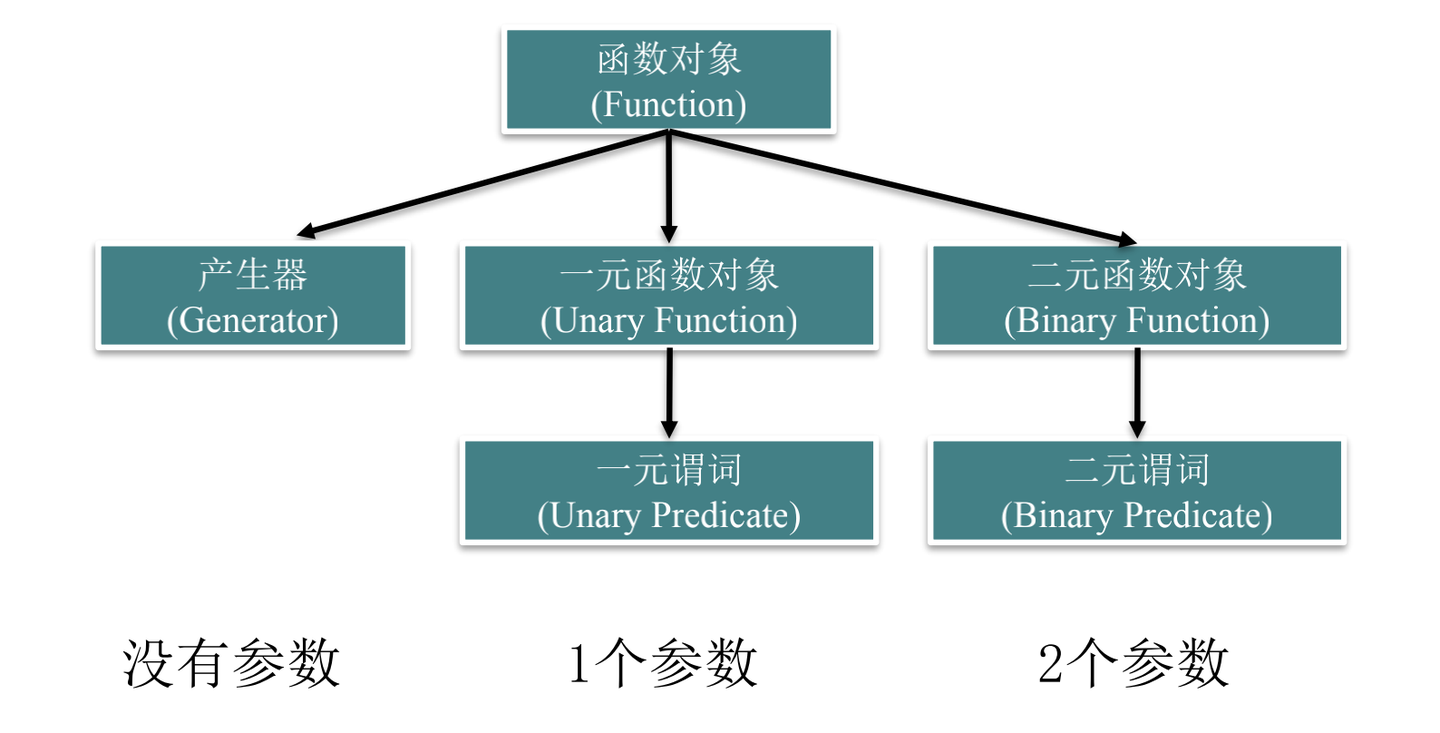
函数对象
函数对象基本概念及分类
函数对象其实就是一个行为类似函数的对象,它可以不需要参数,也可以带有若干参数,其功能是获取一个值,或着改变操作的状态。
任何普通的函数和任何重载了调用运算符operator()的类的对象都满足函数对象的特征
下面给出两个结果相同的程序:
1 |
|
1 |
|
一个普通函数,一个类重载()。
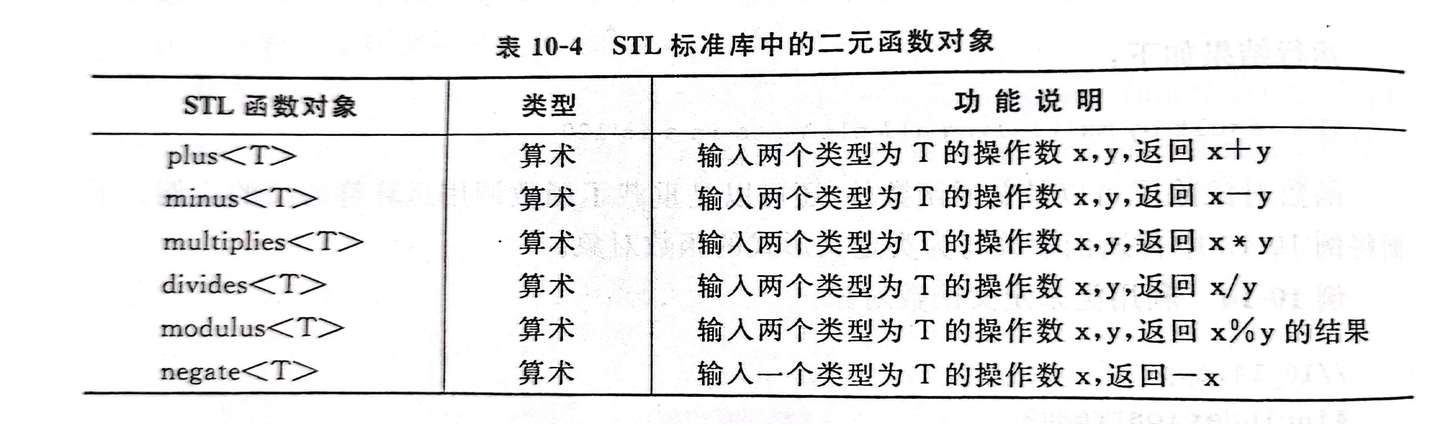
STL提供的函数对象:
- 用于算数运算的函数对象
- 用于关系运算、逻辑运算的函数对象(要求返回值为boolaxs)

lambda表达式
lambda表达式详解
定义:[捕获列表] (参数列表) -> 返回类型 {函数体}
- 捕获列表可捕获lambda所在函数的局部变量
- 参数列表、返回类型和函数题与普通函数一致
- 可定义在函数内部,理解为未命名的内联函数
- auto lmda = [] { return “Hello World!”; };
- cout<< lmda() <<std::endl; //执行与函数对象一致
捕获列表有值捕获、引用捕获和隐式捕获方式
- int size = 10, base = 0; //局部变量
- auto longer = [size](const string &s){return s.size()>size;} //值捕获
- auto longer = [&size](const string &s){return s.size()>size;}//引用捕获
- auto longer = [=](const string &s){return s.size()>base;}//隐式值捕获
- auto longer = [&](const string &s){return s.size()>size;}//隐式引用捕获
函数适配器
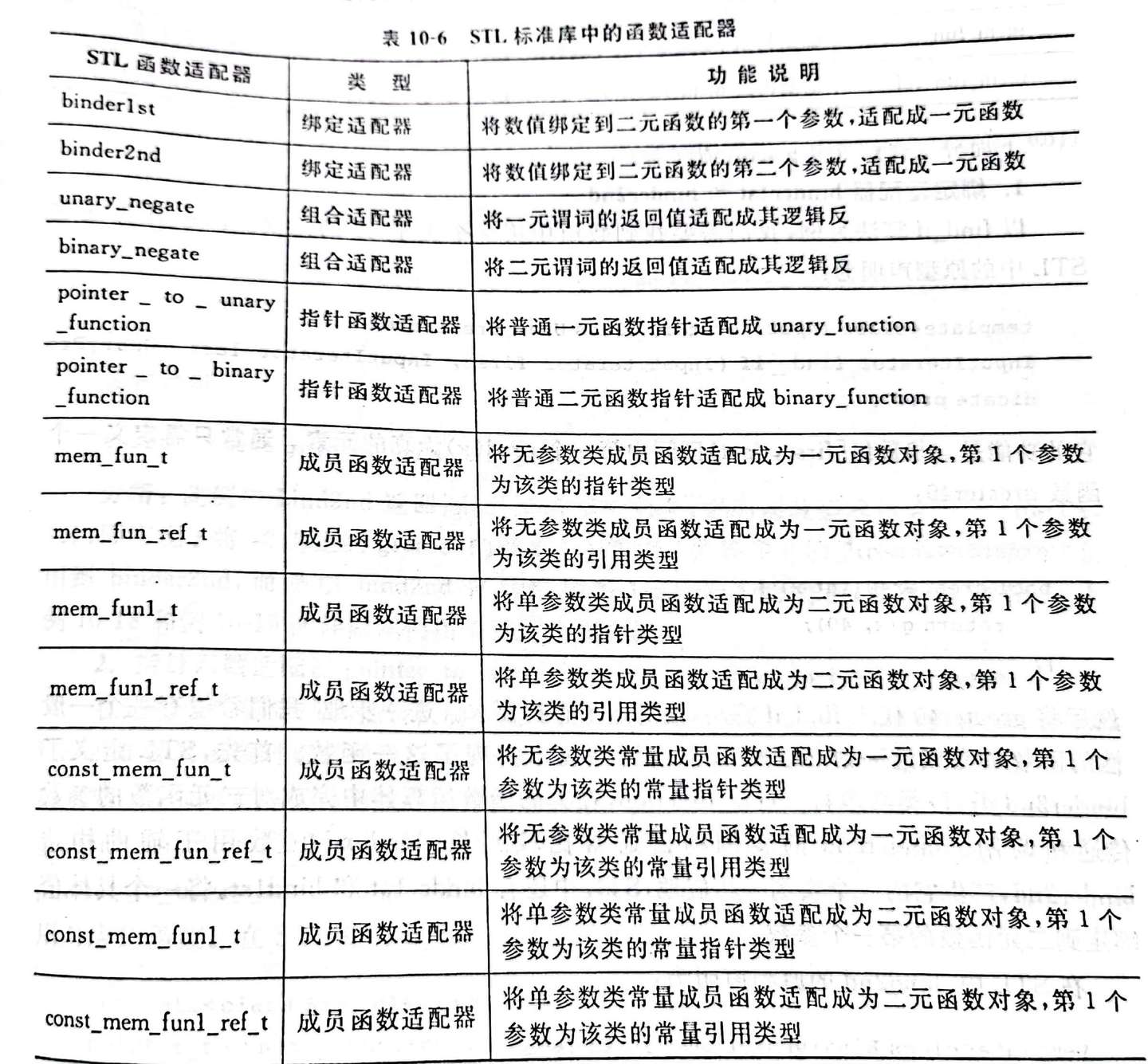
bind2nd产生binder2nd函数适配器的实例
1 |
|
函数模板还有很多内容,实践中再慢慢学习
算法
算法的特点:
- STL算法本身是一种函数模版
- 通过迭代器获得输入数据
- 通过函数对象对数据进行处理
- 通过迭代器将结果输出
- STL算法是通用的,独立于具体的数据类型、容器类型
算法的分类:
- 不可变序列算法
- 可变序列算法
- 排序和搜索算法
- 数值算法
代码所用算法都可以在图片中到找,故不做解释。
不可变序列算法
不直接修改所操作的容器内容的算法,用于查找指定元素、比较两个序列是否相等、对元素进行计数等。

例:
1 | template<class InputIterator, class UnaryPredicate> |
可变序列算法
可以修改它们所操作的容器对象,包括对序列进行复制、删除、替换、倒序、旋转、交换、分割、去重、填充、洗牌的算法及生成一个序列的算法。


例:
1 | template<class ForwardIterator, class T> |
Removing is done by shifting (by means of copy assignment (until C++11)move assignment (since C++11)) the elements in the range in such a way that the elements that are not to be removed appear in the beginning of the range. Relative order of the elements that remain is preserved and the physical size of the container is unchanged. Iterators pointing to an element between the new logical end and the physical end of the range are still dereferenceable, but the elements themselves have unspecified values (as per MoveAssignable post-condition).
排序和搜索算法
- 对序列进行排序
- 对两有序序列进行合并
- 对有序序列进行搜索
- 有序序列的集合操作
- 堆算法


1 | template <class RandomAccessIterator , class UnaryPredicate> |
sort要求first和last必须是随机迭代器类型,因为sort的具体实现使用了快速排序,使用随机迭代器是效率上的考虑。
数值算法
求序列中元素的“和”、部分“和”、相邻元素的“差”或两序列的内积,求“和”的“+”、求“差”的“-”以及求内积的“+”和“·”都可由函数对象指定。

例:
1 | template<class InputIterator, class OutputIterator, class BinaryFunction> ▫ OutputIterator partial_sum(InputIterator first, InputIterator last, OutputIterator result, BinaryFunction op); |
[数值算法实例](https://github.com/hustlixiang21/cpp-practice/tree/main/数值算法应用实例





